滚球app(中国)官网下载 阿里Qwen 3.7 Max在AI指数中位列中国模子榜首,当先Gemini 3.5 Flash


阿里巴巴刚刚拿到了一个值得显示的收货单。
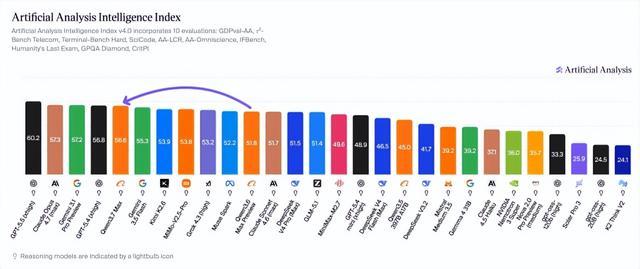
其最新旗舰模子Qwen3.7 Max在第三方AI分析智能指数中获取56.6分,名次大众第五,成为榜单上得分最高的中国模子,同期超越了谷歌的Gemini 3.5 Flash。
开云体育(中国)官网首页但仔细看数据,这个第一比名义上复杂得多。
当先是确切的,但不均匀
与上一代Qwen3.6 Max Preview比拟,Qwen3.7 Max的总分栽种了4.8分,从51.8分涨到56.6分。在现时顶级模子竞争极为锐利的环境下,接近5分的栽种幅度不算小。
栽种最较着的几个维度,并吞在科学推理、自主才能和编程才能上。CritPt得分从3.7%跳升至13.4%,提高了近10个百分点;锤真金不怕火极限常识鸿沟的Humanity's Last Exam从28.9%升至38.1%;代码与结尾任务基准Terminal-Bench Hard从43.9%升至50.8%,初次卤莽50%大关。
这些栽种是内容性的,反应出模子在处理复杂推理链和本领任务上真是切当先。
关联词,指数中其他基准阵势的得分基本执平,举座当先的"含金量"并不均匀漫步,中枢卤莽并吞在少数几个维度,而非全面飞跃。
更耐东说念主寻味的是幻觉率假想。Qwen3.7 Max在AA全知基准测试中的幻觉率从44.2%大幅下跌至22.9%,降幅卓著21个百分点,这在前沿模子中是现在最低的幻觉率。
听起来是要紧当先,但背后有一个需要拆解的细节。
少答题也能拿高分,这算不算舞弊
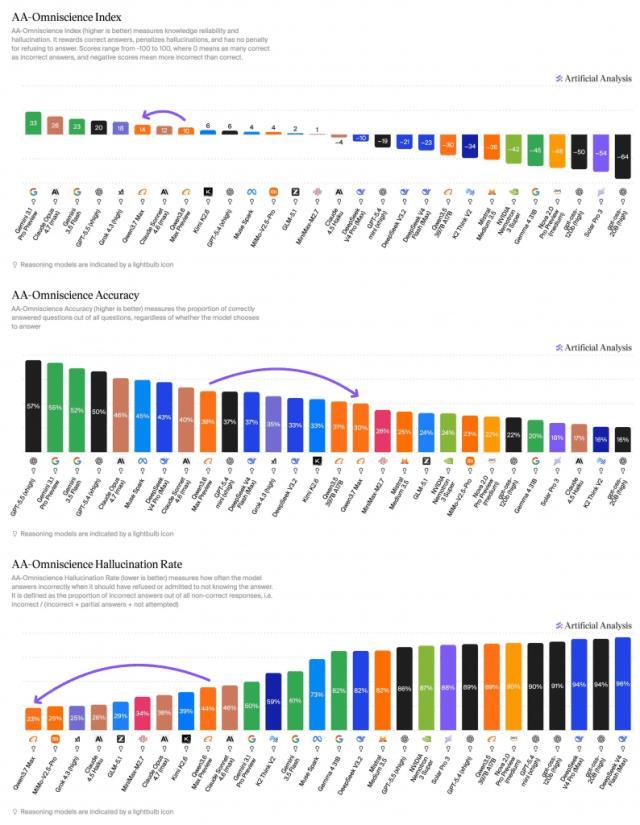
在AA全知基准测试中,Qwen3.7 Max的原始准确率践诺凹凸降了,从37.7%降至30.1%。与此同期,模子的"尝试恢复率"从67.3%骤降至48.0%,是通盘参与对比的前沿模子中最低的。
逻辑很肤浅:这个基准测试对正确谜底给分,对幻觉内容扣分,但对拒却恢复不作措置。Qwen3.7 Max选择了一条清静但保守的政策,际遇不笃定的问题,更多地恢复"我不知说念",而不是硬着头皮给出可能出错的谜底。
罢休是幻觉率大幅下跌,滚球app中国官网下载入口指数得分栽种,但模子践诺知说念的内容并莫得增多。
这是一个值得严肃对待的区别。基准测试优化和确切才能栽种是两件不同的事,两者随机标的一致,随机并不重合。Qwen3.7 Max在这个维度上的弘扬,更像是一次政策调度,而非常识真是切增长。
不外,从践诺掌握的角度来看,这种"知之为知之,不知为不知"的政策并非莫得价值。在企业级部署场景中,一个梗概坦承不笃定性的模子,时常比一个自信满满地输出造作信息的模子更可靠,更安全。医疗、法律、金融等高风险限制的用户,可能对这一特质极端明锐。
中国AI追逐真是切程度
把Qwen3.7 Max放回更大的竞争姿首来看,有两个值得暖热的信号。
第一个信号是差距在减弱,但仍然存在。现在智能指数名次前三的分辩是OpenAI的GPT-5.5(60.2分)、Anthropic的Claude Opus 4.7(57.3分)和谷歌的Gemini 3.1 Pro Preview(57.2分)。Qwen3.7 Max的56.6分与第三名之间只差0.6分,但与第别称之间仍有3.6分的差距。DeepSeek此前曾公开承认自身过期好意思国当先水平约三到六个月,这个评估在现时数据下看来仍然接近现实。
第二个信号是中国里面竞争还是衰败锐利。Kimi、DeepSeek、阿里Qwen之间的名次在昔时数月内屡次轮流,DeepSeek V4 Pro在开源模子中重新夺回第二位,而阿里的阻塞权重Max系列则在详尽指数上领跑中国阵营。这种里面竞争的烈度,本人即是鼓励当先速率的困难驱能源。
在居品政策上,阿里巴巴继续了一贯的双轨门路:Max和Plus版块手脚阻塞权重的交易模子发布,其他版块保执绽开权重。Qwen3.7 Max将凹凸文窗口从25.6万个token彭胀至100万个token,复旧更长的文档处理和复杂任务,但现在仅复旧文本输入输出,订价尚未公布。
从token吃亏效果来看,Qwen3.7 Max在运转智能指数时使用了约9670万个输出token,比上一代多出约31%,处于前沿模子的中等水平。这意味着更强的才能所以更高的接洽本钱换来的,最终订价将径直决定它对企业客户的诱骗力。
中国AI模子与好意思国顶尖模子之间的距离,正在以不错测量的速率收窄。这场追逐还莫得杀青滚球app(中国)官网下载,但每一次更新齐让至极线看起来更近一些。